Can AI create unit tests?
Since conducting this research, GPT4o has been released. We have discovered that it significantly outperformed every model tested in this blog post (see the last test in our whitepaper). So, while these preliminary tests are revealing, further research using GPT4o is required.
Unit tests are a powerful part of the software testing arsenal, helping to ensure software reliability and maintaining code quality throughout the development lifecycle. But they can also be quite time-consuming to create and maintain.
Could the recent advances in AI ease this burden?
To answer this question, we conducted a series of experiments using a variety of large language models (LLMs).
Introduction
Unit tests validate the behaviour of individual components within software, helping developers catch bugs early, reduce defects, and provide a safety net when refactoring or enhancing code.
However, creating a comprehensive suite of these tests can be time-consuming and repetitive. Due to the detailed nature of unit testing, it’s common to have more test code than source code in a well-tested codebase. A device might require thousands of individual unit tests, which can take weeks to write and maintain as the codebase evolves. Additionally, achieving acceptable coverage requires testers to have detailed knowledge of the system, attention to edge cases, and a high degree of persistence.
Given these constraints, the potential for AI to automate the generation of unit tests is of significant interest.
We set out to discover the effectiveness of large language models (LLMs) in generating unit tests, and assess their ability to produce reasonable, useful, and comprehensive test cases.
After several weeks of testing, we have determined that, while it’s still early days, AI offers a promising solution to reduce the time and effort involved in test creation.
Experiment 1: Which AI writes the best unit tests?
Our initial focus was to determine which LLMs produced the most effective unit tests, both in terms of code coverage and mutation scores. We evaluated multiple LLMs: ChatGPT-4o, Claude Opus, Llama 3.1 and Gemini 1.5, using the GoogleTest framework. The subject of our tests was TinyXML2, an open-source C++ XML parser, chosen for its compactness and availability of hand-written unit tests for comparison
We assessed the project’s hand-written unit tests for code coverage and mutation score, and then got the LLMs to write replacement tests.
Tools
Mull
Mutation testing tool using LLVM API to inject mutations at compile time. It accounts for code coverage, meaning only tested code is mutated.
llvm-cov
Code coverage utility which informs mull which code to mutate. It also provides a secondary statistic on quality of unit tests.
Google Test (gtest)
A specialised C++ testing framework developed that allows developers to write and run unit tests for their C++ code.
Cover Agent
A CLI tool that iteratively guided AI models by providing coverage feedback and refining the generated tests based on predefined goals (e.g., a target coverage percentage)
Results
The hand-written tests were superior to all four LLMs, scoring significantly higher for function coverage, line coverage, region coverage, and branch coverage.
| Test creator | Function coverage | Line coverage | Region coverage | Branch coverage | Mutation score (all files) |
| GPT | 39.1% | 36.9% | 40.0% | 29.6% | 52% |
| Claude | 35.2% | 33.0% | 36.2% | 25.1% | 68% |
| Llama | 27.7% | 23.7% | 27.0% | 16.4% | 11% |
| Gemini | 30.7% | 26.4% | 27.8% | 18.0% | 54% |
| Human | 94.1% | 85.9% | 88.1% | 76.2% | 78% |
Of the LLMs, ChatGPT achieved the highest coverage score, with Claude a close second. However, when it came to mutation scoring, Claude performed significantly higher than the other models, detecting almost as many bugs as the hand-rolled unit tests.

Experiment 2: Testing code with standards
For the next part of the study, we explored whether LLMs would create better unit tests based on a standard/specification rather than source code.
Method
For this, we chose TinyJSON, a lightweight JSON parser and generator for C and C++, with a single header/source, and written using TDD.
In one condition, we provided Claude with the JSON specification and header file and prompted it to write a set of unit tests using gtest to cover as much of the specification as possible. In another condition, we prompted Claude to create its unit tests based on the source code.
Results
Unit tests generated from the specification performed better than those generated from source code. They were readable and more comprehensive, covering key JSON features like parsing nested structures and handling various data types. However, Claude did require some coaching around broken tests.
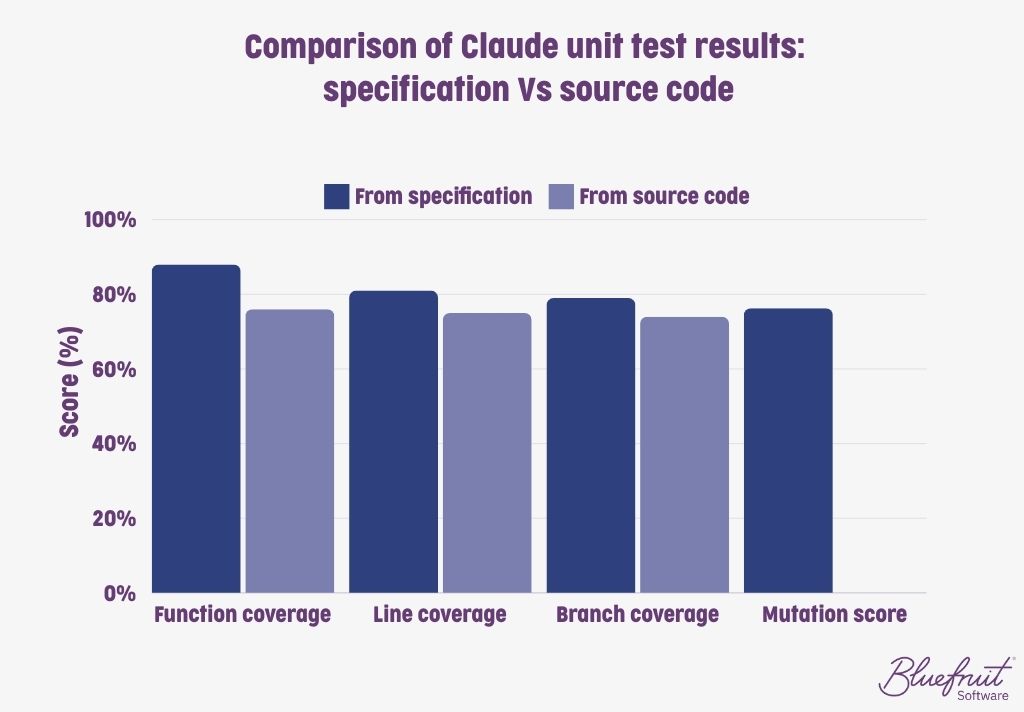
Tests generated from source code tended to focus on lower-level functions, were less readable, and neglected critical functionality such as array handling.
Basing unit tests on a clear specification appears to be a more reliable method for achieving broad coverage and protecting against code mutations. This finding suggests that AI models may perform better when they are provided with high-level guidance that allows them to generate tests that cover a wider range of functional scenarios.
Like humans, AI would seem to be most effective while using a test-first approach.
The hand-written unit tests included with the TinyJSON repo still scored higher than Claude across the board.
Experiment 3: Improving Claude by providing feedback
Our next study explored whether feedback could improve LLM performance in generating unit tests. Specifically, we examined whether allowing Claude to assess the results of its initial tests and then generate a second round of tests could improve coverage and mutation scores.
Method
Claude was given the results of its initial test suite, including coverage gaps and failed tests, and was prompted to improve its output. We then compared this to its previous output.
Results
While coverage improved slightly on a second attempt, the gains were modest. Claude required highly specific prompts to address the identified gaps, and additional improvements often led to test failures that required further back-and-forth refinement. Although this method shows potential, it suggests that LLMs in their current state still struggle when presented with more complex coding tasks.

Crucially, while hand-written tests offered greater coverage, Claude actually generated 0.6% unique tests, suggesting that an experienced human software tester, leveraging AI would provide the best overall result.
Conclusion
Our study demonstrates that AI has the potential to significantly streamline the process of creating and maintaining unit tests. By leveraging advanced language models, we can reduce the time and effort required to ensure software reliability, allowing teams to focus on innovation and development.
If your organisation is looking to enhance its software testing processes, we can help.
Get in touch to learn how we can support your software development and testing needs.
Did you know that we have a monthly newsletter?
If you’d like insights into software development, Lean-Agile practices, advances in technology and more to your inbox once a month—sign up today!
Find out more




