Without comprehensive AI evals, your product is worthless.
Your AI product isn’t intrinsically valuable; your AI evals are.
The rise and rise of LLMs has opened the floodgates for the development of AI applications. Across all sectors, established companies and start-ups alike are racing to bring new AI innovations to market or update existing product lines. But it has also shifted where real value (and real risk) now lives.
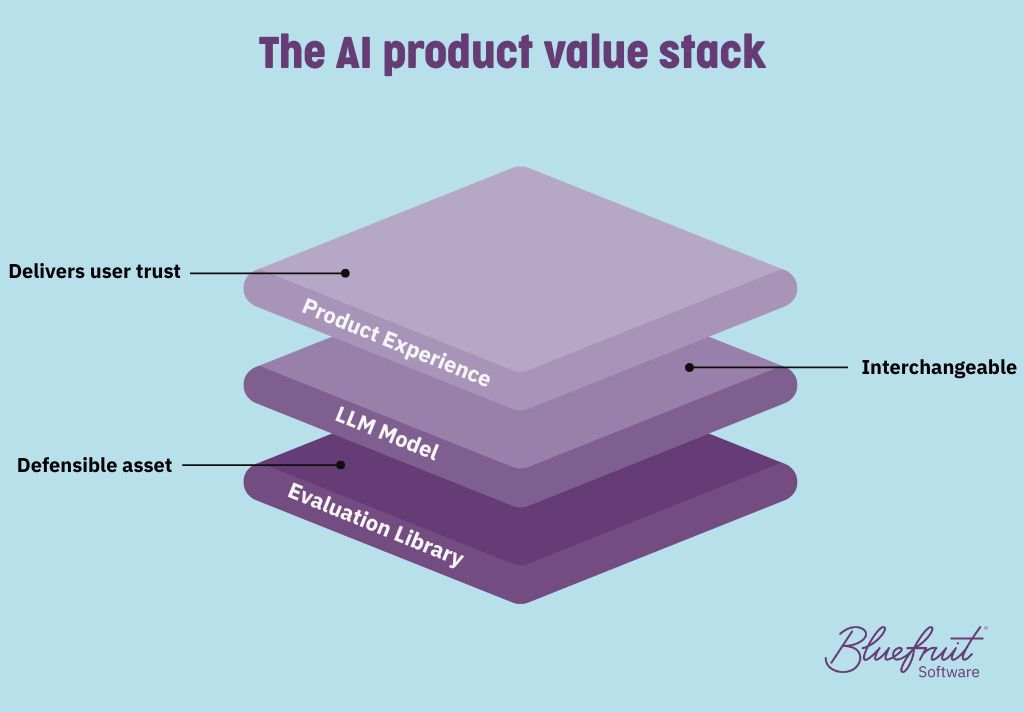
When it comes to AI, your intellectual property lives in the tests, not the model. Without a rigorous, automated evaluation library that interrogates every scenario your system will face, even the smartest model will misbehave and erode user trust.
That’s where AI evals come in.
Comprehensive evals do three jobs at once: they prove reliability, protect reputations, and provide a competitive edge that rivals can’t easily copy. Data-rich test suites capture domain knowledge that no generic foundation model provides, and they give you the freedom to swap LLM vendors (or self-host) without rewriting quality gates.
In this blog, you’ll learn why evals are now the centre of gravity for AI quality programmes and tips on how to design a scenario-led, dataset-driven eval strategy.
Remind me: What’s an eval?
When creating software—whether it’s for a heart monitor, a banking app, or a car stereo—you need to be sure it’s fit for purpose. You must verify that the software is being built right, according to the design, specifications, and necessary standards. And you must validate that the product meets user needs and expectations.
Each carries a long list of tests that must be completed.
Evals make up a large part of the standard verification process.
In AI applications, evals allow developers to systematically measure the accuracy of output, identify any weaknesses, and benchmark improvements. However, due to the nature of AIs (and LLMs in particular), regular evals aren’t fit for purpose; you need AI-specific evals.
The AI eval bottleneck
In a 2024 presentation for Snowflake Inc., renowned computer scientist, Dr Andrew Ng, identified these evals as a significant bottleneck to AI development. He explained that while the speed of machine learning model development has accelerated dramatically thanks to generative AI, the process of evaluating these models has not kept pace.
Collecting and preparing evaluation data, and designing effective testing protocols, often slows down the overall development workflow. Because, despite rapid advances in model training and prototyping, ensuring that models perform reliably and safely in real-world scenarios requires thorough and often time-consuming evaluation.
Ng’s proposed solution? A shift from sequential to parallel workflows. Evaluation data should be built up alongside prototype development, rather than waiting until a model is “finished” before beginning evaluation.
How are evals for AI applications different?
While traditional software is deterministic, LLMs (large language models) operate probabilistically, relying on pattern recognition.
This presents some interesting challenges for writing evals:
There is no single ‘correct’ answer: AI-generated outputs (text, predictions, and recommendations, for example) often vary.
Models degrade: AI models can degrade over time due to data drift or changes in user behaviour. As such, they must be constantly monitored.
Performance is statistical, not binary: Instead of pass/fail, AI evals rely on metrics like accuracy, F1-score, BLEU, or perplexity.
It’s clear that regular quantitative, pass/fail evals aren’t going to cut the mustard.
Eight key techniques for AI evaluation
We asked Bluefruit’s AI testing specialists about creating effective AI evals. Here are their top tips:
- Design your eval library as your IP
Your evals encode product strategy. You can weight them toward “sunny-day” tasks for everyday accuracy or toward “rainy-day” edge cases for robustness. That weighting is a deliberate choice, and it’s why your evals become the defensible asset, rather than the model.
- Run a Darwinian eval loop
Let the tests choose the model and the prompt. Treat prompts, guardrails, and even model providers as variants; run them head-to-head on your evals and keep what wins. This keeps you model-agnostic while holding quality constant.
- Score what you actually care about (and slice it)
Don’t stop at a single aggregate score. Track facet scores (e.g., core “sunny-day” tasks vs “rainy-day” edge cases) so you can make explicit trade-offs. A model that’s 2% worse on the easy stuff but 10% better on the tricky cases may be the right call for your users. Tag tests so reports show where models differ, not just that they differ.
- Choose a cadence and manage cost
Automate a small smoke subset of tests to run on each build, and schedule the full evaluation suite for sprints or releases. Because running large-scale AI evals can be costly (tokens, GPUs, lab time), plan your test schedule carefully to balance speed and expense. Regularly running the tests ensures you catch issues promptly while managing resources effectively.
- Keep the evals alive
Adopt a simple rule: ‘new failure = new test’. Continuously add real bugs, new edge cases, and updated requirements to the eval library so it evolves with the product.
- From requirements to executable evals
Where possible, express requirements in a form you can execute (e.g. BDD/Gherkin-style scenarios). Link requirements to their evals so product intent, engineering, and measurement stay in lockstep.
- Keep testing independent
In line with safety-critical practice (e.g. IEC 61508), use a dedicated test group separate from the engineers once a project moves beyond feasibility. Their focus is to test, measure, and report accuracy independently.
- Stay model-agnostic
Because the eval library defines the pass/fail bar, you can “chop and change” model providers, and even move to self-hosted, without rewriting tests.
The bottom line
As powerful foundation models become commodities, what will set your products and company apart isn’t the code, but the rigour, depth, and evolution of your evaluation library. Evals are where your real IP and your brand live. They empower you to adapt to tech change, maintain quality, and delight users—no matter what’s happening beneath the hood.
By doing AI evals right, your teams can:
- Prove and sustain reliability as models and needs evolve.
- Confidently navigate technology swaps or upgrades.
- Rapidly address bugs, edge cases, and shifting requirements.
- Demonstrate a defensible, systematic approach to AI quality, crucial in regulated or safety-critical contexts.
If you want AI you can trust and a product your users can depend on, your investment in evaluations is not optional; it’s your moat, your safety net, and your long-term advantage.
Need help building, auditing, or evolving your AI eval strategy?
Get in touch with us—we’re always happy to hear about your projects, share our insights, and help you move AI from black-box magic to business asset.
You may also be interested in...
Did you know that we have a monthly newsletter?
If you’d like insights into software development, Lean-Agile practices, advances in technology and more to your inbox once a month—sign up today!
Find out more




